
Scoring ryzyka powtórek: progi decyzji w pipeline AI

W skrócie
- check_circleUstal trzy poziomy decyzji na podstawie score: akceptacja, poprawka automatyczna i eskalacja do redakcji.
- check_circleZdefiniuj granice progów procentowych, aby thresholding działał identycznie w każdym uruchomieniu pipeline AI.
- check_circleWprowadź przypadki krytyczne wymagające ręcznej akceptacji, gdy treść nie może zostać opublikowana automatycznie.
- check_circleWersjonuj reguły progów i loguj każdą decyzję (score, data, wersja, powód), by umożliwić audyt i rollback.
- check_circleUruchom monitoring dryfu danych oraz sprawdzaj zgodność z EU AI Act i art. 22 RODO przy automatyzacji publikacji.
W skrócie:
- Ustal trzy poziomy decyzji na podstawie score: akceptacja, poprawka automatyczna i eskalacja do redakcji.
- Zdefiniuj granice progów procentowych, aby thresholding działał identycznie w każdym uruchomieniu pipeline AI.
- Wprowadź przypadki krytyczne wymagające ręcznej akceptacji, gdy treść nie może zostać opublikowana automatycznie.
- Wersjonuj reguły progów i loguj każdą decyzję (score, data, wersja, powód), by umożliwić audyt i rollback.
- Uruchom monitoring dryfu danych oraz sprawdzaj zgodność z EU AI Act i art. 22 RODO przy automatyzacji publikacji.
Wprowadzenie
Jeśli chcesz skalować treści SEO i GEO w automatycznym pipeline AI, najpierw musisz ustalić, kiedy ryzyko powtórek jest jeszcze do przyjęcia, a kiedy wymaga korekty. To właśnie tutaj wchodzi w grę scoring ryzyka powtórek oraz progi decyzji w pipeline AI — czyli mechanizm, który mówi systemowi: „akceptuj”, „sprawdź ponownie” albo „eskaluj do człowieka”. Można to porównać do kontroli jakości w kuchni: nie każda zupa musi trafić do kosza, ale jeśli smak zaczyna odbiegać od standardu, trzeba zareagować od razu.
Dlaczego progi są ważne
Sam model nie wystarczy, bo nawet dobry system może z czasem zacząć produkować zbyt podobne akapity, nagłówki lub układy treści. Progowanie decyzji oznacza ustawienie granic, które porządkują pracę pipeline’u i zmniejszają liczbę przypadkowych błędów. Dzięki temu publikacje są bardziej spójne, a koszty skalowania rosną wolniej niż zasięg.
Co powinien obejmować checklist
- Próg akceptacji — poziom ryzyka, przy którym treść przechodzi dalej bez ingerencji.
- Próg eskalacji — moment, w którym materiał trafia do dodatkowej kontroli.
- Monitoring dryfu — stałe sprawdzanie, czy zachowanie modelu nie odchyla się od ustalonych norm.
- Kontrola zgodności — weryfikacja, czy wynik nadal spełnia zasady jakości i bezpieczeństwa.
Tak zbudowany system działa jak sygnalizacja świetlna: zielone światło przyspiesza pracę, żółte każe zwolnić, a czerwone zatrzymuje publikację.
Scoring ryzyka powtórek i progi decyzyjne w AI — ustawienia startowe (pre-launch)
Ustal startowe progi, aby system oceniał ryzyko powtórek tak samo za każdym razem.
Ta kategoria checklisty dotyczy ustawień przed startem, czyli momentu, w którym definiujesz, kiedy treść przechodzi dalej, kiedy trafia do poprawy, a kiedy wymaga ręcznej akceptacji. W praktyce to właśnie progowanie decyzji w scoringu ryzyka powtórek zamienia ocenę modelu w przewidywalny proces. Bez tego pipeline AI do scoringu ryzyka i podejmowania decyzji zaczyna działać chaotycznie, a koszty kontroli rosną szybciej niż zasięg.
- Ustal bazowy poziom ryzyka dla nowych sekcji na podstawie typu treści, wrażliwości tematu i celu publikacji.
- Zdefiniuj próg akceptacji dla treści o niskim ryzyku powtórek, aby mogły przechodzić bez dodatkowej ręcznej weryfikacji.
- Określ próg eskalacji dla treści średniego ryzyka, kierując je do redakcji lub analityka przed publikacją.
- Ustaw próg blokady dla wysokiego ryzyka, gdy podobieństwo do istniejących materiałów grozi duplikacją lub osłabieniem GEO i SEO.
- Włącz monitoring dryfu danych (czyli sprawdzanie, czy dane wejściowe nie zmieniają się stopniowo poza zakładany wzorzec), aby progi nie starzały się po cichu.
- Dodaj kontrolę zgodności z wymaganiami organizacji i regulacji, w tym z logiką odpowiedzialności opisaną w EU AI Act oraz przy ocenie decyzji wpływających na użytkownika w duchu art. 22 RODO.
- Zapisuj uzasadnienie decyzji dla każdego wyniku scoringu, tak aby można było odtworzyć, dlaczego treść została zaakceptowana, wstrzymana lub poprawiona.
- Sprawdź wyjaśnialność modelu za pomocą metod takich jak SHAP, żeby widzieć, które cechy najbardziej podnoszą ryzyko powtórek.
- Ustal harmonogram przeglądu progów po wdrożeniu, na przykład po pierwszych seriach publikacji, aby korygować thresholding na podstawie realnych wyników.
- Połącz scoring SEO i GEO z automatyzacją publikacji treści, tak aby każda zmiana progów od razu wpływała na kolejny etap pipeline AI.
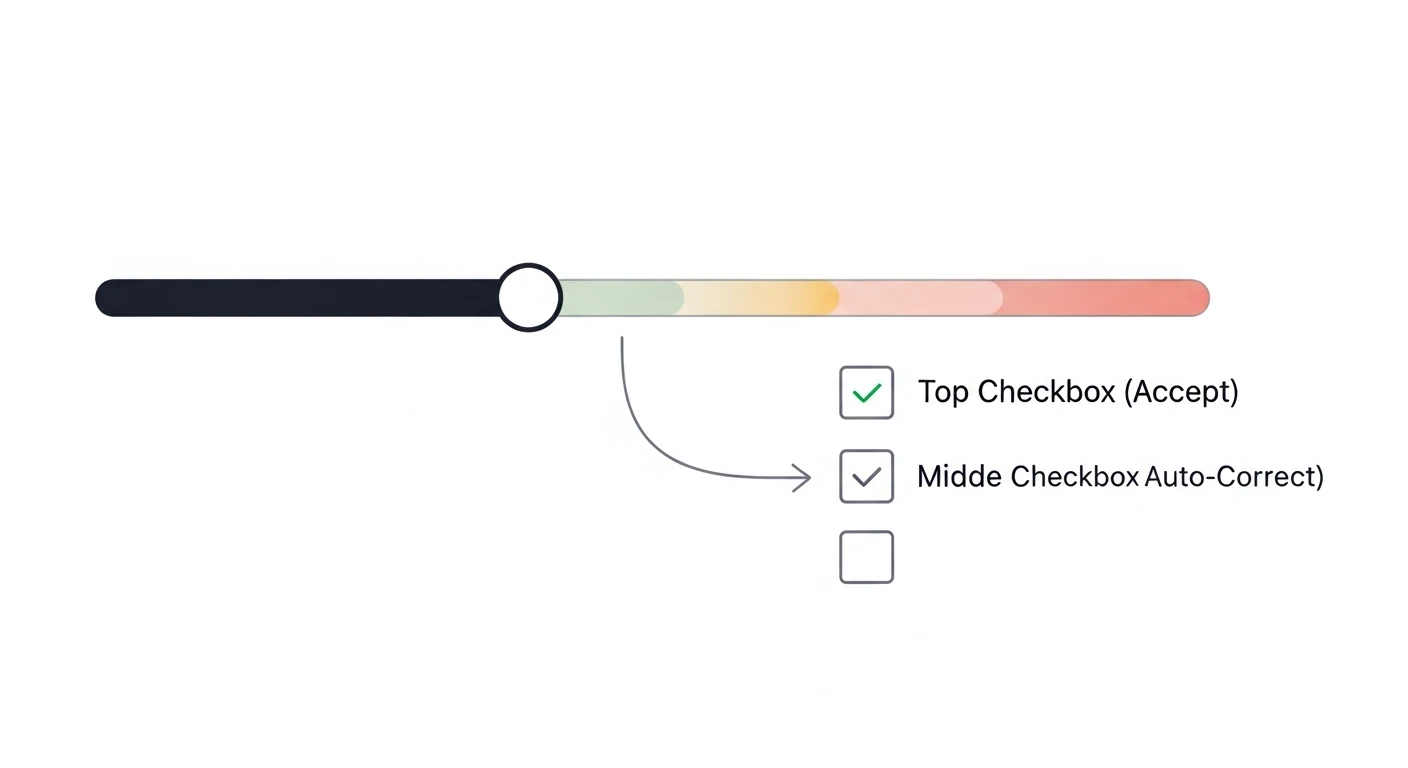
Pipeline AI scoring ryzyka i kontrola jakości — reguły publikacji i eskalacji
Reguły publikacji i eskalacji zamieniają scoring ryzyka powtórek w powtarzalną decyzję, a nie w uznaniową opinię.
Ta kategoria checklisty pokazuje, jak ustawić progi decyzyjne w scoringu ryzyka powtórek tak, aby pipeline AI oceniał treści zawsze według tych samych zasad. Dzięki temu publikacja, poprawka lub eskalacja do człowieka nie zależą od „wyczucia modelu”, tylko od jawnych reguł, które można audytować, wersjonować i aktualizować bez chaosu.
- Ustal trzy poziomy decyzji dla wyniku score: akceptacja, poprawka automatyczna i eskalacja do redakcji.
- Zdefiniuj granice procentowe dla każdego poziomu, aby thresholding działał identycznie w każdym uruchomieniu pipeline AI.
- Opisz osobno przypadki krytyczne, w których treść nie może zostać opublikowana bez ręcznej akceptacji.
- Przypisz właściciela reguł publikacji, który zatwierdza zmiany progów i odpowiada za ich spójność.
- Włącz wersjonowanie reguł, aby dało się cofnąć zmianę, jeśli nowy próg zwiększy liczbę fałszywych alarmów.
- Dodaj logowanie każdej decyzji, wraz z wynikiem score, datą, wersją reguły i powodem eskalacji.
- Uruchom monitoring dryfu danych, czyli kontrolę, czy dane wejściowe nie zaczęły odbiegać od wzorca, na którym ustawiono progi.
- Sprawdzaj zgodność z EU AI Act i zasadami nadzoru, zwłaszcza gdy system wspiera decyzje o publikacji w obszarach wrażliwych.
- Uwzględnij art. 22 RODO, jeśli automatyzacja może wywoływać skutki podobne do decyzji podejmowanych wyłącznie maszynowo.
- Dodaj warstwę wyjaśnialności, na przykład SHAP, aby zespół widział, które cechy podniosły ryzyko powtórek i dlaczego.
- Ustal harmonogram przeglądu progów po zmianach w treściach, źródłach lub wymaganiach GEO i SEO.
- Zapisz ścieżkę eskalacji dla zespołu, tak aby każdy wiedział, kto reaguje przy przekroczeniu progu i w jakim czasie.
Monitoring dryfu i fairness w systemach scoringowych — zgodność oraz nadzór człowieka
Monitorowanie dryfu i fairness utrzymuje scoring ryzyka powtórek w granicach zgodności, nawet gdy dane i model zaczynają się zmieniać.
Ta kategoria checklisty pokazuje, jak połączyć progi decyzyjne w scoringu ryzyka powtórek z nadzorem człowieka, aby pipeline AI scoring ryzyka i kontrola jakości działał przewidywalnie także po wdrożeniu. W praktyce chodzi o to, by system nie tylko oceniał treści, ale też sygnalizował, kiedy jego ocena przestaje być wiarygodna. To ważne szczególnie tam, gdzie GEO i scoring SEO w automatyzacji publikacji treści wpływają na skalę publikacji i ryzyko błędów.
- Zdefiniuj monitoring dryfu danych dla wejść, wyjść i jakości decyzji, aby wykrywać zmianę wzorców zanim wzrośnie liczba fałszywych akceptacji.
- Ustal osobne progi alarmowe dla dryfu, jakości i zgodności, zamiast opierać się na jednym wskaźniku dla całego systemu.
- Zapisuj uzasadnienie każdej decyzji scoringowej wraz z kodem przyczyny, aby później dało się odtworzyć, dlaczego treść trafiła do publikacji albo do eskalacji.
- Włącz nadzór człowieka dla przypadków granicznych, czyli takich, które mieszczą się blisko progu akceptacji lub odrzucenia.
- Przypisz odpowiedzialność za przegląd alertów do konkretnej osoby, bo zgodnie z EU AI Act systemy wysokiego ryzyka muszą działać pod nadzorem człowieka.
- Sprawdź, czy logika decyzji nie prowadzi do nierównego traktowania podobnych treści, a w razie potrzeby porównuj wyniki między typami stron, tematami i językami.
- Stosuj SHAP do wyjaśniania wpływu cech na wynik modelu, aby łatwiej wskazać, co podbiło ryzyko powtórki i gdzie potrzebna jest korekta.
- Zweryfikuj, czy przetwarzanie danych nie uruchamia obowiązków z art. 22 RODO, jeśli scoring zaczyna realnie wpływać na automatyczną decyzję bez udziału człowieka.
- Przeglądaj ustawienia po każdej istotnej zmianie modelu, źródeł danych lub szablonu treści, bo nawet mała korekta może przesunąć zachowanie całego pipeline’u.
- Dokumentuj wyniki audytu i działania naprawcze w jednym rejestrze, aby zespół mógł szybko sprawdzić, kiedy próg decyzji wymaga ponownego strojenia.
Podsumowanie
Jeśli chcesz wdrożyć scoring ryzyka powtórek i progi decyzji w pipeline AI bez chaosu, zacznij od prostego założenia: system ma nie tylko liczyć ryzyko, ale też prowadzić zespół do spójnych decyzji. To trochę jak sygnalizacja świetlna na ruchliwym skrzyżowaniu — sama obecność świateł nie wystarczy, liczy się jeszcze to, kiedy zapala się żółte i czerwone. Dzięki temu treści nie trafiają do publikacji przypadkiem, tylko po przejściu jasnej ścieżki oceny.
Największą wartością takiego podejścia jest połączenie trzech elementów: progów decyzyjnych, testów jakości i monitoringu po wdrożeniu. Progi mówią, co zrobić z wynikiem modelu, testy sprawdzają, czy reguły działają w praktyce, a monitoring wychwytuje moment, gdy dane lub zachowanie systemu zaczynają się zmieniać. To daje porządek zamiast zgadywania, a porządek w procesie zwykle przekłada się na lepszą jakość publikacji.
Gotowe do wdrożenia? Umów demo Lemify albo skorzystaj z pomocy pod adresem /pomoc/google-search-console, aby przejść przez ustawienie progów, testy jakości i plan monitoringu krok po kroku. To najprostsza droga, by zbudować proces, który działa przewidywalnie i można go rozwijać wraz z zespołem.
Najczęściej zadawane pytania
Co to jest scoring ryzyka powtórek i jak działa w pipeline AI?
Scoring ryzyka powtórek to mechanizm oceny treści na podstawie wyniku (score), który wskazuje prawdopodobieństwo powtórek. W pipeline AI score jest porównywany z progami decyzyjnymi, aby uruchomić jedną z akcji: akceptację, poprawkę automatyczną lub eskalację do redakcji. Każda decyzja jest rejestrowana (score, data, wersja, powód), co umożliwia audyt i rollback.
Jak dobrać progi decyzyjne dla różnych typów przypadków w scoringu?
Ustal trzy poziomy decyzji: akceptacja, poprawka automatyczna i eskalacja do redakcji, a następnie zdefiniuj granice procentowe dla każdego poziomu. Dodatkowo opisz przypadki krytyczne, które nie mogą być publikowane automatycznie i zawsze wymagają ręcznej akceptacji. Progi powinny być jawne, wersjonowane i stosowane identycznie w każdym uruchomieniu pipeline AI.
Czy progi decyzyjne powinny się zmieniać w czasie (np. przy dryfcie danych)?
Tak, progi mogą wymagać aktualizacji, gdy monitoring wykryje dryf danych lub zmianę zachowania systemu. Wdrożenie powinno obejmować wersjonowanie reguł progów oraz testy jakości, aby ocenić wpływ zmian i umożliwić rollback. Zmiany progów powinien zatwierdzać właściciel reguł publikacji, aby zachować spójność decyzji.
Jakie metryki oceny jakości decyzji warto stosować w scoringu ryzyka?
Warto mierzyć skuteczność decyzji na podstawie tego, czy progi prowadzą do właściwych akcji: akceptacji, poprawki lub eskalacji. Artykuł wskazuje na potrzebę testów jakości oraz monitoringu po wdrożeniu, a także logowania decyzji (score, data, wersja, powód), co pozwala analizować błędy i fałszywe alarmy po zmianach progów.
Co to jest nadzór człowieka w kontekście systemów scoringowych AI?
Nadzór człowieka oznacza ręczną akceptację decyzji w przypadkach krytycznych, gdy treść nie może zostać opublikowana automatycznie. W praktyce pipeline AI eskaluje takie przypadki do redakcji, zamiast wykonywać automatyczną akceptację lub poprawkę. To element kontroli jakości i ograniczania ryzyka błędnych publikacji.
Jak przygotować dokumentację techniczną i audytowalność decyzji w pipeline AI?
Dokumentacja powinna obejmować wersjonowane reguły progów decyzyjnych oraz opis ścieżki: jak score jest mapowany na akcje (akceptacja, poprawka, eskalacja). Każda decyzja musi być logowana wraz z: wynikiem score, datą, wersją reguł i powodem. Dodatkowo wdroż monitoring dryfu danych oraz sprawdzaj zgodność z EU AI Act i art. 22 RODO przy automatyzacji publikacji.
Powiązane zasoby
Najczęściej zadawane pytania
Co to jest scoring ryzyka powtórek i jak działa w pipeline AI?expand_more
Jak dobrać progi decyzyjne dla różnych typów przypadków w scoringu?expand_more
Czy progi decyzyjne powinny się zmieniać w czasie (np. przy dryfcie danych)?expand_more
Jakie metryki oceny jakości decyzji warto stosować w scoringu ryzyka?expand_more
Co to jest nadzór człowieka w kontekście systemów scoringowych AI?expand_more
Jak przygotować dokumentację techniczną i audytowalność decyzji w pipeline AI?expand_more
Eat your own dog food
Ten artykuł wygenerował Lemify
17-krokowy pipeline SEO + GEO z obrazami AI, te same modele i prompty co dostają nasi klienci. Wypróbuj 14 dni za darmo i sprawdź jakość outputa na własnym temacie.